Guso, E., Luberadzka, J., Sayin, U. & Serra, X.

We open-source a synthetic reverberation dataset that improves the performance of data-driven speech models. We show that Multi-Band (MB) absorption coefficients on shoebox-based synthetic RIRs lead to better performance in DNN-based speech enhancement compared to using single-band (SB) absorption coefficients. We additionally study implementing source and receiver directivities.
IEEE Workshop on Applications of Signal Processing to Audio and Acoustics (WASPAA 2025)
· code ·Luberadzka, J., Guso, E. & Sayin, U.

A model for acoustic style transfer in speech. The reverberation (r1) of a speech signal (s1) is transformed into s1r2 by Film-conditioning a U-net with another reverberant speech signal s2r2. Our model outperforms two baselines and performs on par with a semi-oracle case.
IEEE Workshop on Applications of Signal Processing to Audio and Acoustics (WASPAA 2025)
· project page · code ·Schmele, T., De Filippi, E., Nandi, A., Pereda-Banos, A. & Garriga, A.

Machine learning methods were optimized on spectral EGG features according to four music source positions and valence type in a subject-wise manner, finding that EEG correlates with four source locations, specially when a negative emotional valence is played outside of the listener's field of view.
Music and Sound Generation in the AI Era, Springer Nature, 2023.
De Muynke, J., Ferrando, J., & Katz, B.F.G.

The study reconstructs the acoustics of the Great Chapel at the Palais des Papes to examine how its changing architecture influenced 14th-century Ars Nova choral performance. Through real-time virtual auralisation, singers experienced historically accurate acoustics, offering new insights into the interplay between medieval music and its performance spaces.
Journal of Sound Studies, 2025.
De Muynke, J., Poirier-Quinot, D., & Katz, B.F.G.
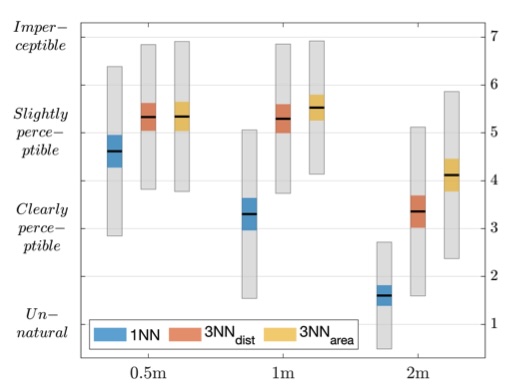
The study explores how interpolation between spatial Room Impulse Responses affects the perceived stability of sound sources in navigable reverberant virtual environments. Using third-order Ambisonic RIR convolution with MagLS binaural decoding, VR listening tests inform the design of realistic spatial audio for immersive experiences such as virtual museum visits.
Journal of the Audio Engineering Society, 2024.
Schmele, T., & Garriga, A.
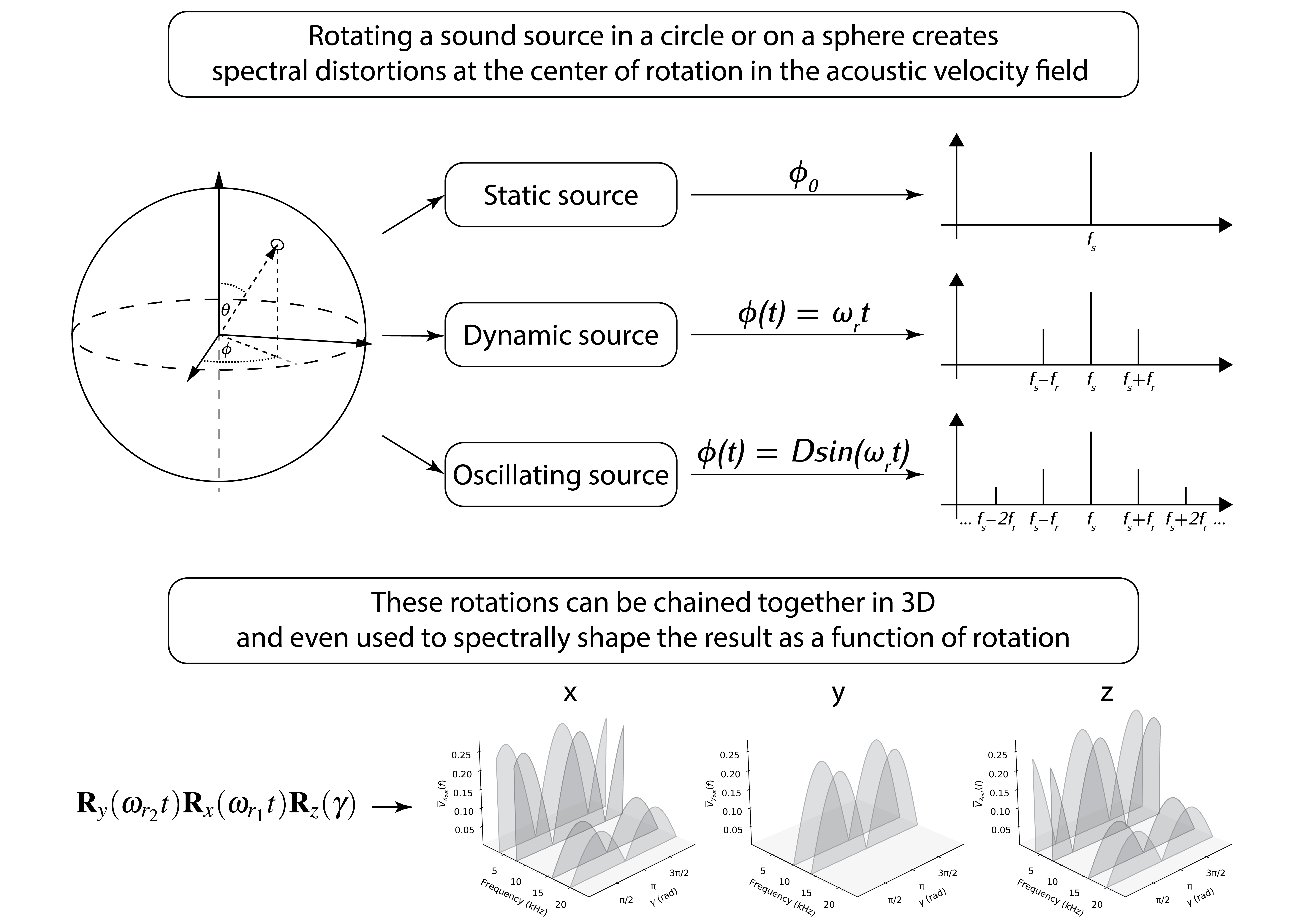
Definition of a method to synthesize new sounds using only spatial transformation matrices in 2D and 3D audio space.
Journal of the Audio Engineering Society, 72(4), 193-210, 2024.
Redondo, R.
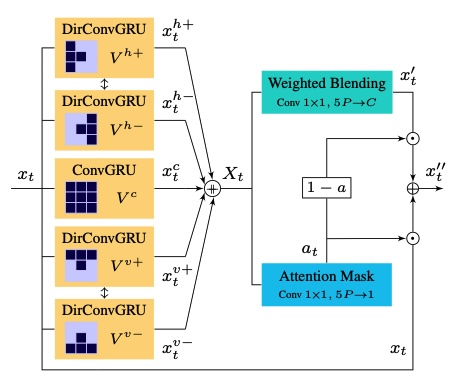
GANs architectural improvements for temporal coherency on generic sound-to-video generation, including triple sound routing, a multiscale dilated RNN, and a novel recurrent and directional video prediction layer.
AV4D: Visual Learning of Sounds in Spaces. ICCV Workshop, 2023.
Gusó, E., Luberadzka, J., Baig, M., Sayin, U., & Serra, X.
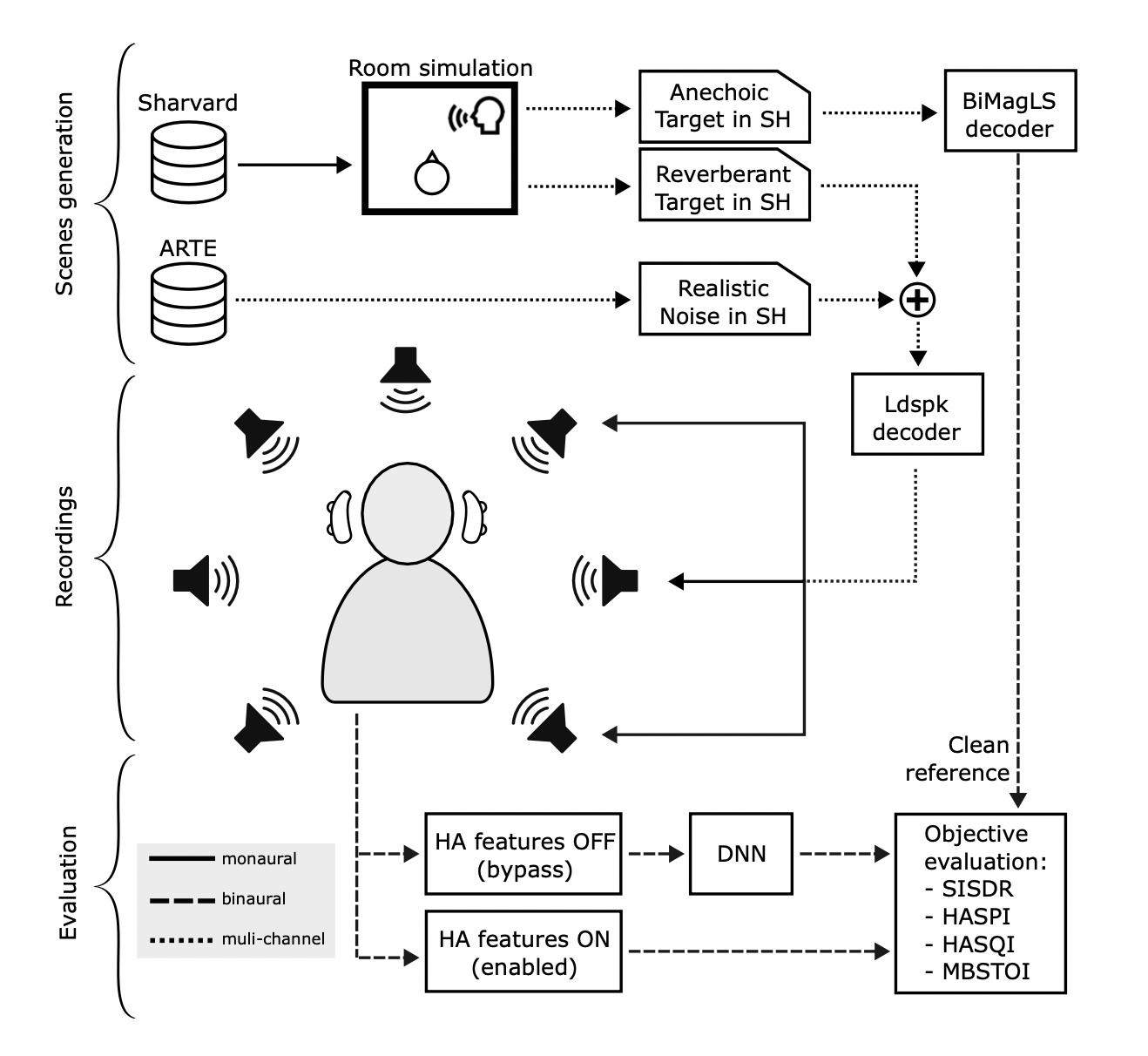
The performance of five high-end commercially available Hearing Aid (HA) devices are compared to DNN-based speech enhancement algorithms in complex acoustic environments, in which the latter outperforms the HA algorithms in terms of noise suppression and objective intelligibility metrics.
IEEE Workshop on Applications of Signal Processing to Audio and Acoustics (WASPAA) (pp. 1-5), 2023.
· code ·F. Chataigner, P. Cavestany, M. Soler, C. R., J. P. Gonzalez, C. Bosch, J. Gibert, A. Torrente, R. Gomez and D. Serrano.
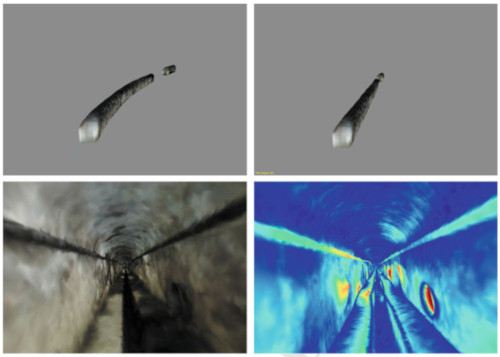
The Autonomous Robot for Sewer Inspection (ARSI), a robotic system designed to make the work of inspection brigades safer and more efficient.
Advances in Robotics Research: From Lab to Market, Springer, 2020.
Gomez, R., Biten, A.F., Gomez, L., Gibert, J., Rusiñol, M., & Karatzas, D.
This paper proposses two different architectures for image style transfer applied to text while maintaining the original transcriptions.
IEEE International Conference on Document Analysis and Recognition (ICDAR) (pp. 805-812), 2019.
Phone (+34) 932 381 400
Carrer de Bilbao, 72, 08005 Barcelona.
Multimedia Tecnologies Unit © 2019.
About this site.