Rafael Redondo - Eurecat CC BY 2023.
Abstract
Deep generative models have demonstrated the ability to create realistic audiovisual content, sometimes driven by domains of different nature. However, smooth temporal dynamics in video generation is a challenging problem. This work focuses on generic sound-to-video generation and proposes three main features to enhance both image quality and temporal coherency in adversarial models: a triple sound routing, a multi-scale residual and dilated recurrent network for extended sound analysis, and a novel recurrent and directional convolutional layer for video prediction. Each of the proposed features improves, in both quality and coherency, the baseline neural architecture typically used in the SoTA.
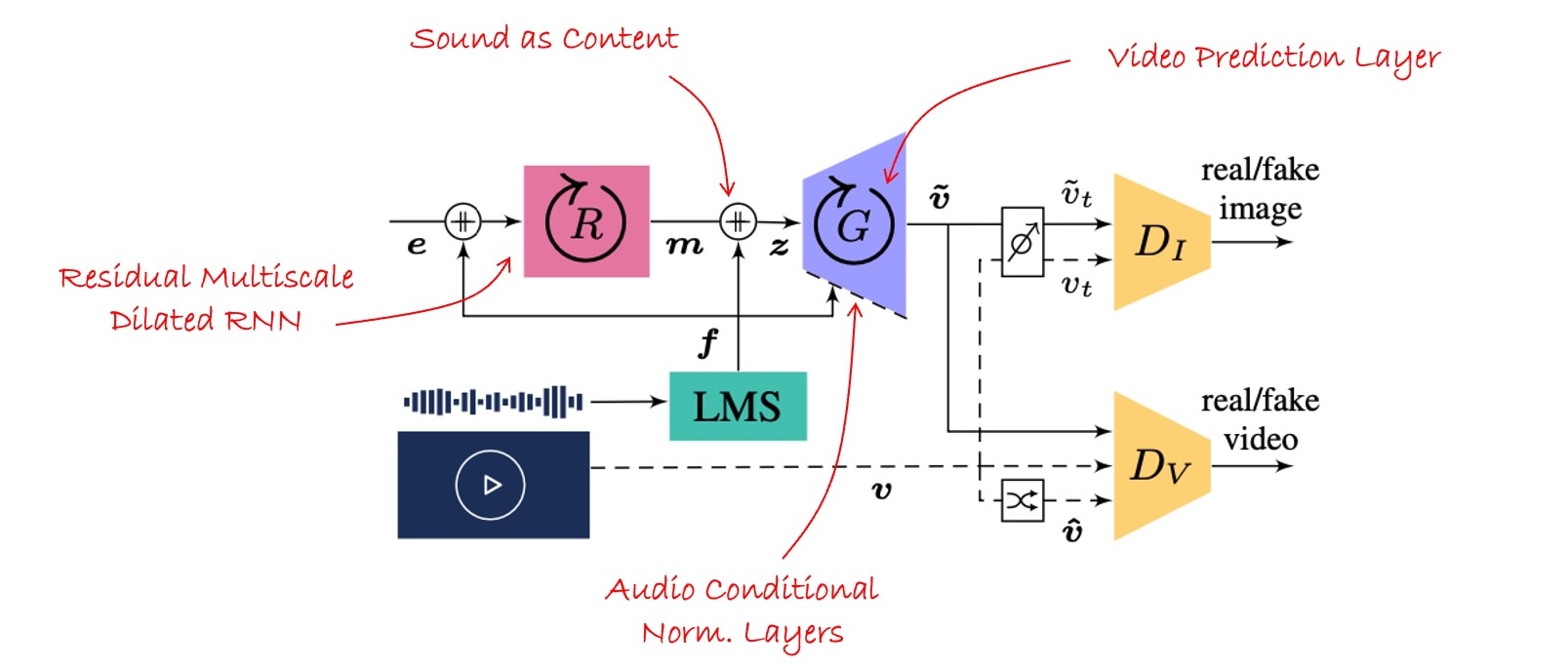
Main architecture. The training video is batched in consecutive \(T\)-frame sequences. Audio features \(f\) (LMS) are routed to: (1) a recurrent neural network \(R\) as source of motion concatenated with noise \(e\), (2) the generator \(G\) as source of content concatenated with motion tokens \(m\), and (3) generative instance normalization layers. \(R\) comprises a residual multi-scale DilatedRNN. \(G\) contains Directional ConvRNNs. The video discriminator \(D_V\) learns from reals \(v\), fakes \(\tilde{v}\), and shuffled versions \(\hat{v}\). The image discriminator \(D_I\) receives real \(v_t\) and synthetic \(\tilde{v_t}\) frames with the same random index.
Sound representation and audio temporal coherency
The waveform is effectively converted into B=64 log mel frequency (LMS) bins, with a 25ms window length and 10ms hop size. It is then split in chunks of 85ms. The effective temporal resolution will eventually be constrained by the video frame rate fixed to 50ms (20fps). The sound features are finally calculated by averaging chunks over time. Note that chunk overlapping —in this case 37.5%— already encourages temporal coherency.
Routing types are not either mutually exclusive or redundant, in fact their combination is beneficial, as shown later. Sound features replace content noise, so that the generator’s input is concatenated across the temporal dimension. In this way, the generator has direct access to the raw sound features at each time step. In addition to that, sound features are recurrently encoded, sometimes concatenated with motion noise. In this way, the recurrent network has to infer motion from sound.
A multi-layer RNN with dilated skip connections is proposed to deal with more complex temporal dynamics of sound, which sometimes unfolds at different resolution speeds. Also, residual connections facilitate the propagation of audio features through the network.
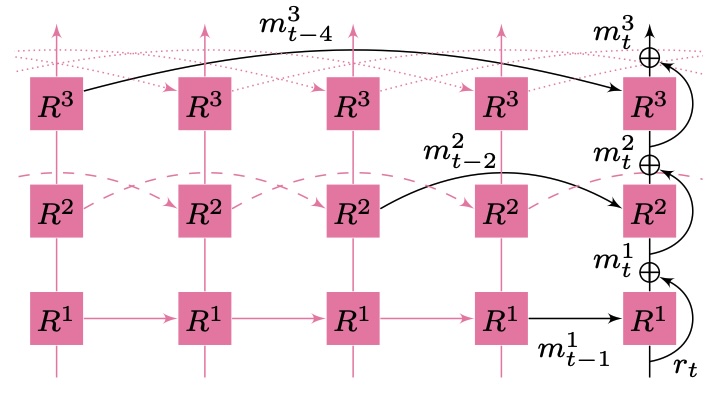
Motion encoding: a 3-layer DilatedRNN with residual connections. Note recurrent cells have the same input-output size.
Adversarial video architecture
The generator and both discriminators are built upon a series of feedforward layers, made of convolutional, normalization, and activation layers. While \(D_I\) and \(D_V\) use batch normalization, \(G\) additionally uses noise injection and audio conditional instance normalization. To reinforce access to conditional data traveling through the generator, sound features are encoded into class feature vectors, ultimately modulating an instance normalization layer. \(D_V\) is built on 3D kernels, one temporal and two spatial dimensions equally sampled at each layer.
A novel recurrent multi-directional convolutional layout is proposed for causal video prediction. The activation distribution at each time step are the hallucinated activations of a generative layer and directional predictions. The video prediction layer comprises 4-directional ConvGRUs (DirConvGRU), predicting positive and negative motion in horizontal and vertical directions, and a squared-centered ConvGRU dealing with motion along the camera axis. A weighted blending layer not only merges all directional predictions but also predicts an auto-regressed attention mask to merge both the hallucinated and predicted pixels.
An amenable implementation is built under the assumption that opposite directions can share weights and directionality can be achieved by aggregating increasingly larger and shifted one-dimensional kernels. The video prediction layer is stacked after the outermost generative layer, although it can be potentially inserted in each of the generative layers.
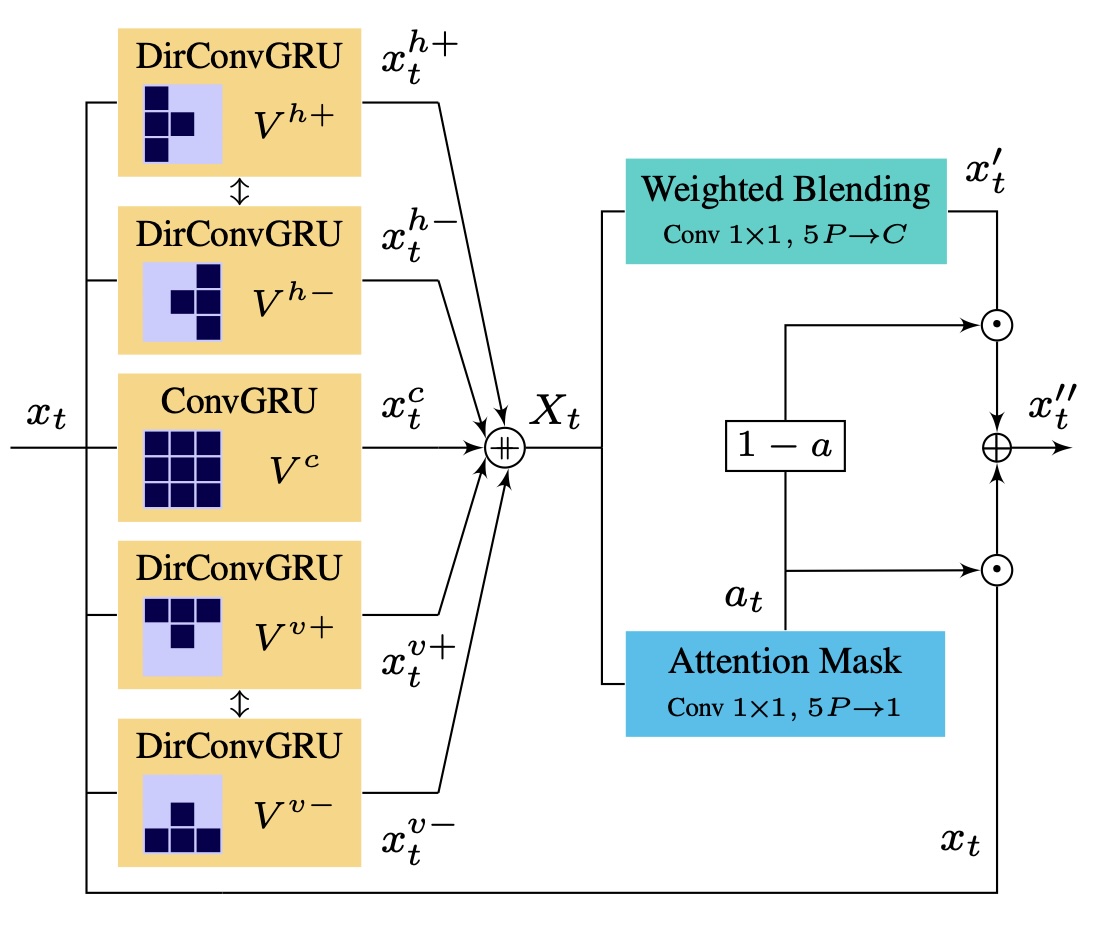
Video prediction layer: 4-directional and 1-centered ConvGRUs (kernel size 3). Spatial predictions are channel-wise concatenated and blended by means of 1x1 convolutions to accommodate output channels. Merged predictions \(x'_t\) and previous hallucinated activations \(x_t\) contribute to the output \({x''}_t\) according to an auto-regressive mask \(a_t\) shared across channels with the Hadamard product. Note opposite directions share weights.
Experimentation
The goal of this work is to improve GANs ability to regenerate videos based exclusively on its audio as guidance, as realistic and coherent as possible, to later be able to re-animate the same visual content in synchrony with a replaced audio input. Text- or pose-based audio-to-video methods are not directly comparable within our aim. Furthermore, this study entails a particular one-shoot training on a single video. Therefore, a baseline implementation —a common MfS scheme and the state of the art advances here described— is used to compare with each of the proposed features. More details about training hyperparameters and final network configuration are described in the paper.
The layer connection has a strong impact on the synthesis quality, where the main architectural difference with this work is the spatio-temporal cross-domain generation. Skip connections in the generator tend to produce large colored patches, increasing their presence and intensity as the input audio deviates from the original audio. By switching to residual connections the artifacts simply disappear. Conversely, discriminators built upon residual connections often produce severe blurring and erase some details. Instead, a residual generator and skip-connected discriminators usually produce sharper images.

Illustration of artifacts produced by a 512x512 vanilla GAN with (left) skip-connections, (middle) residual connections, and (right) a residual generator and skip-connected discriminators.

Ablation study at 128x128 resolution on diverse audiovisual content: cello (melodic), a classic quintet (harmonic), drums (percussive), and a side-view talking head (speech). Taking motion from sound (MfS) as a baseline, the sound routing features are activated one at a time: Residual+Dilated-RNN, sound as content (SaC), and audio conditional instance normalization (acIN). As for the video prediction group, all routing features are activated to compare between a basic ConvGRU and the proposed DirConvGRUs. Averages calculated over batches of the 20%-split source video.
Synthesized images get affected when the distribution of feedforward sound deviates from the training source. This could be of interest to re-animate a video by using sounds from different contexts or acoustics. To evaluate this, random audio clips were selected from FSD50K. Since large variations in distribution are plausibly expected, specially in terms of temporal dynamics, we cannot trust on FVD, while SSIM and LPIPS are simply infeasible in the absence of ground-truth pairs. Instead, FID can measure distortions by comparing how far real and synthetic images are at high-level representation. The full model proves more robustness on in-the-wild sound replacement when trained on a music video, while apparently the generalization capability reduces when trained on speech.

Baseline (MfS) vs full model sound robustness. FID averaged over 500 audio clips of 1-5s randomly selected from FSD50K.

Examples of consecutive frames synthesized by our full-model at 256x256 resolution and 20fps fed with validation audio samples of the videos.
Additional synthetic video footage
J.S. Bach - Cello Suite Nº6 Pau Casals - El cant dels ocells Nirvana - Come as you are Ascending scale (original audio track) (different excerpt, lower res)
Once I saw - A.I.Levin Drums MEAD M31 El cant dels ocells Trombone MEAD W33 (original sound sources) (replaced sounds)
Trombone (SubURMP) Relaxing ocean El cant dels ocells Green forest Once I saw (original sound) (original sound)
Discussion
In this work various strategies to improve temporal coherence of sound-to-video GANs have been proposed, which can be applied straightforwardly to other domains. Many other configurations were tested, including sound encoding, conditioning augmentation, spectral and pixel normalization, joint audio-image discriminators, or feature matching loss. Most of them did not show improvements and, in general, any strategy to encode (compress) audio features led to an impairment.
While our method struggles to reproduce large and complex motion dynamics, specially those unrelated to sound, it is particularly demanding on both computation and memory despite our amenable DirConvRNN.
Generative models like this can certainly leverage smart tools for audiovisual content creation. On the other hand, unlike images, there is still a significant gap to achieve high-quality realistic videos. Even so, it may already raise important ethical concerns on inappropriate usage, from faking reality to illicit activities.
Acknowledgements
This work was financially supported by the Catalan Government through the funding grant ACCIÓ-Eurecat (Project PRIV - DeepArts).